Multimodel RL
背景
TODO: 待学习
Reinforcement Learning: An Overview[^8]
RL算法
在强化学习(RL)的应用中,特别是在多模态大语言模型(MLLMs)的理解能力增强中,常常提到两种主要的RL训练范式:价值模型无关的方法(value-model-free methods)和价值模型相关的方法(value-model-based methods)[^1]。这两种方法的主要区别在于它们是否依赖于价值函数的显式建模。
价值模型无关的方法(value-model-free methods)
这类方法不依赖于价值函数或者模型来估计未来奖励。它们直接通过策略梯度(policy gradient)来优化策略,即通过直接评估策略(policy)对应的行为(action)的概率分布,并根据奖励信号来调整这个分布。这种方法的代表算法是**Group Relative Policy Optimization (GRPO)**。
- GRPO:在GRPO中,策略的更新不依赖于价值函数的估计,而是通过比较组内不同的输出响应(samples)来计算优势函数(advantage function),然后基于这个优势函数来更新策略。这种方法的优势在于实现简单,不需要额外的价值模型训练,能够稳定地进行策略优化。
价值模型相关的方法(value-model-based methods)
与价值模型无关的方法不同,价值模型相关的方法会估计一个价值函数来预测未来的累积奖励。这种方法通常会结合价值函数和策略梯度来更新策略,能够提供更为精确的奖励估计,从而优化策略。代表性的算法包括Proximal Policy Optimization (PPO)[^7]。
- PPO:PPO是一种结合了价值函数和策略梯度的算法。它通过优化一个代理的价值函数来估计当前策略下的状态值,并结合这个价值估计来更新策略。PPO的关键在于通过一个辅助的价值函数来稳定训练过程,并提高训练的样本效率。
两种方法各有优势,适用于不同的场景和任务。价值模型无关的方法通常更加简单直接,适合于那些难以建模价值函数的复杂任务。而价值模型相关的方法则在奖励信号较为稀疏或者需要更精确的奖励预测时表现出色,能够更有效地引导模型学习。在实际应用中,选择哪种方法往往取决于具体任务的特性、可用数据的质量以及计算资源的限制。
未来
在强化学习增强多模态大语言模型(MLLMs)的理解能力方面,存在一些核心挑战,这些挑战指向了未来研究的三个主要方向:稀疏奖励(sparse rewards)、不高效的跨模态理解(inefficient cross-modal reasoning)以及现实世界部署约束(real-world deployment constraints)[^1]。以下是对这三个方向的解释:
稀疏奖励(Sparse Rewards)
问题描述:在RL中,稀疏奖励指的是奖励信号不频繁或者只在任务完成时才提供反馈,这会导致模型难以从少数的奖励信号中学习到有效的策略。在多模态理解任务中,稀疏奖励使得模型难以区分哪些行为是积极的,哪些是消极的,从而难以优化其理解策略。
未来方向:为了解决稀疏奖励的问题,未来的研究可能会集中在以下几个方面:
- 奖励分解:将复杂任务分解为多个子任务,并为每个子任务提供密集的奖励信号,以便模型能够更容易地学习到正确的行为。
- 过程导向奖励机制(Process Reward Mechanisms)可以被视为一种奖励分解的实现方式。过程导向奖励机制强调评估和奖励模型在推理过程中的中间行为,而不仅仅是最终结果的正确性。这种方法可以帮助模型更好地学习到解决问题的正确步骤,从而提高推理能力。例如,在多模态推理任务中,模型可能会被奖励为生成逻辑连贯的推理步骤,而不仅仅是给出正确的最终答案。
- 奖励共享:在多任务学习中,允许不同任务之间共享奖励信号,以增加奖励的频率和多样性。
- 分层奖励建模:开发更复杂的奖励模型,能够在不同的抽象层次上提供奖励,从而引导模型进行更深层次的学习。
- curriculum reinforcement learning(课程强化学习)也与奖励分解相关。这种方法通过逐步增加任务难度,让模型先从简单的任务开始学习,然后逐步过渡到更复杂的任务。这样的训练策略可以看作是对奖励分解的一种实现,其中每个课程阶段都可以为模型提供更密集的反馈和奖励信号。
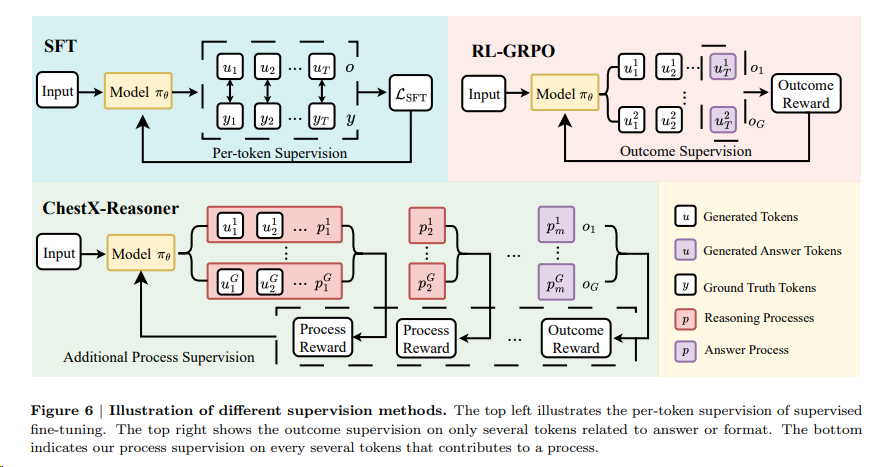
不高效的跨模态理解(Inefficient Cross-Modal Reasoning)
问题描述:
- 跨模态理解涉及到整合和协调来自不同感官通道(如文本、图像、音频和视频)的信息。当前的MLLMs在处理跨模态数据时可能会效率低下,因为它们需要理解和融合来自不同模态的复杂信息。
- 多模态超越文本的挑战:与纯文本数据相比,多模态数据的质量和数量不足,导致模型在视频内容的对齐上表现不佳。
未来方向:为了提高跨模态理解的效率,未来的研究可能会探索以下策略:
- 多模态融合技术:开发更有效的多模态融合机制,以便更好地整合和协调不同模态的信息。
- 利用强化学习从人工智能反馈(RLAIF[^6])中获取多模态对齐的新方法:
- 其中上下文感知的奖励模型(Context-Aware Reward Modeling):通过将视频细分成多个片段,并为每个片段生成详细的描述,然后将这些描述整合到奖励模型中,以提供更清晰的视频内容理解。
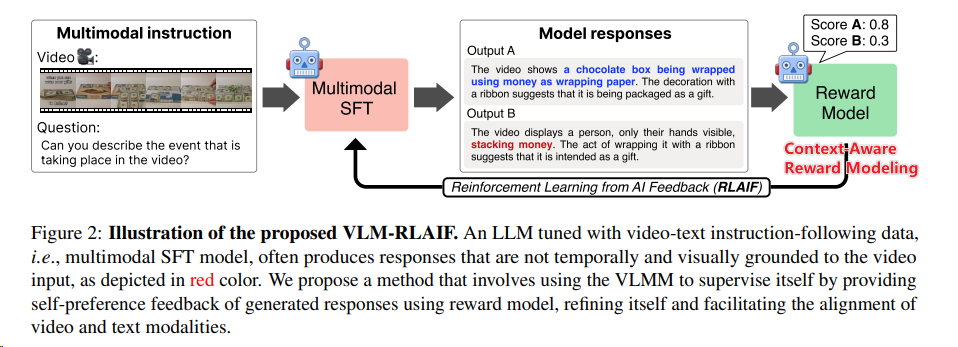
- 视觉引导理解链:利用视觉信息来引导和构建理解链,提高理解过程中的逻辑连贯性和效率。
- 轻量级RL框架:设计更加轻量级的RL框架,以减少计算资源的消耗,并提高模型在处理跨模态任务时的响应速度。
多智能体RL
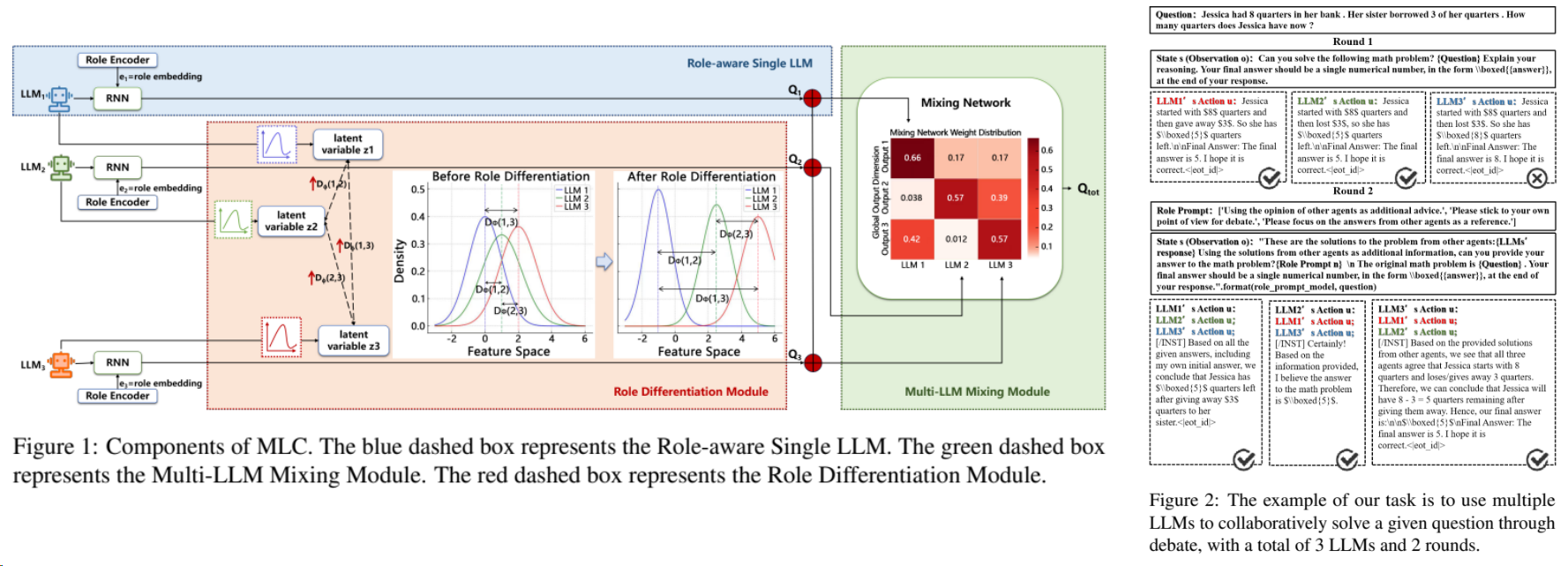
通过RL来训练出不同差异的agent,在联合作答中取得SOTA[^3]
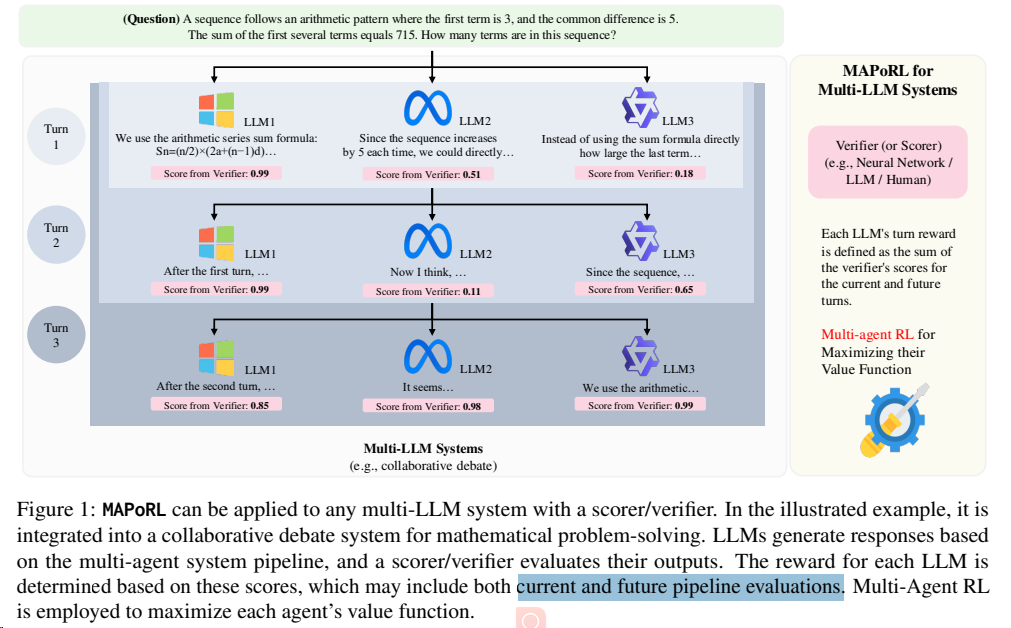
MAPoRL使用了多智能体 PPO(Proximal Policy Optimization)算法来更新每个代理的策略。这个算法通过最大化每个代理的价值函数来进行训练,价值函数是基于累积奖励定义的。通过这种方式,每个代理都能学习如何在与其他代理的交互中最大化其长期奖励。[^4]
商业落地
金融场景的多agent RL实践。[^5]
参考文献
[^1]: Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models
[^2]: ChestX-Reasoner: Advancing Radiology Foundation Models with Reasoning through Step-by-Step Verification
[^3]: ACL25: Advancing Collaborative Debates with Role Differentiation through Multi-agent Reinforcement Learning
[^4]: ACL25: MAPoRL2: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning
[^5]: ACL25: FLAG-TRADER: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
[^6]: ACL24: Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback